Matching IDs across files
- 03 Nov, 2018

Recently I was given two files, A and B. The goal was to produce a third file C that has all lines from B that have matching IDs in A.
FileA.txt
0009
0007
0017
0020
0018
FileB.txt
0007|Some other data
0014|other data
0018|other data
0005|Some other other data
0017|Some other dataother data
0014|Some other data
0020|Some other data|175|other data
0005|other data
0007|Some other data
The desired output, FileC.txt:
0007|Some other data
0018|other data
0017|Some other dataother data
0020|Some other data|175|other data
0007|Some other data
I thought of two ways to tackle this.
Option 1: Use grep
Windows bash, Nix, and OSX all have a command line grep utility. Grep with the -f option takes a file and applied it as patterns to extract a second file. Each line becomes a match which is what we need.
Open a command prompt and run:
grep -f FileA.txt FileB.txt> FileC.txt
The statement above will use each line of FileA.txt as a Regular Expression on FileB.txt. If the line matches, it will be extracted to FileC.txt
A small bug
If there was a line in File B that contained the following:
0000|Some other data 0020 other data
The line above would also match. This occurs because we aren’t telling grep that the patterns in FileA.txt necessarily need to match at the beginning of the line.
I modified FileA.txt so each ID has a carrot (the hat) ^ symbol. This symbol requires that a match be at the start of the line
FileA.txt
^0009
^0007
^0017
^0020
^0018
Now I have the correct output again.
Another bug
Consider this line:
00075022|other data
This is not an ID in my set, but it will match because it begins with 0007 which is in the set. Grep needs to be told only to find matches of “words”. There is a switch for this (-w)
grep -w -f FileA.txt FileB.txt> FileC.txt
Now the output is correct again.
Option 2: Use Sublime
If the command line gives you pause, another way to solve this is to use a text editor like Sublime Text. Similar to grep, Sublime Text can select and search by regular expressions. One thing I liked about this approach is it is visible - I could see the selected lines. I could also further manipulate the lines in Sublime after getting them using its multi-cursor feature.
I needed an expression that matched if any ID matched. Regular Expression supports an “or” syntax:
^(cat|dog|mouse).*
This expression will match rows that begin with the words cat, dog or mouse. Great, but I needed an expression that includes all IDs from a file.
The line splitting and multi-cursor feature of Sublime makes it easy to manipulate structured text data like a list of IDs. Here is what I did:
- Select All
CTRL + A - Split One cursor per line
CTRL+ SHIFT + L - Deselect and move to the start of the line
LEFT ARROW - Delete the line separator and place all data on one line
BACKSPACE - Type
|to put a bar between each item that we need for the RegEx
CTRL+SHIFT+L is the secret sauce that splits the selection into separate cursors per line.
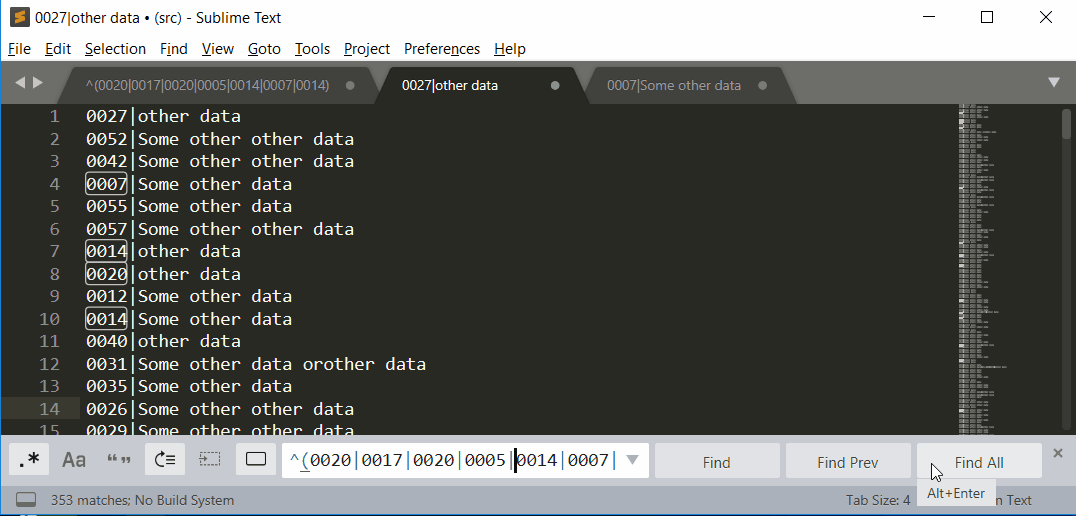
Once I had the IDs on one line and separated by the bar symbol, I encircled with parenthesis and added the line start ^ symbol (Assuming the IDs you want to match are at the start of the line) and the wild card and end of line symbol. This selects the entire line instead of just the beginning of the line.
^(0020|0017|0020|0005|0007)
I then pasted the express into sublime and made sure RegEx and find whole word were selected. I then clicked find all.
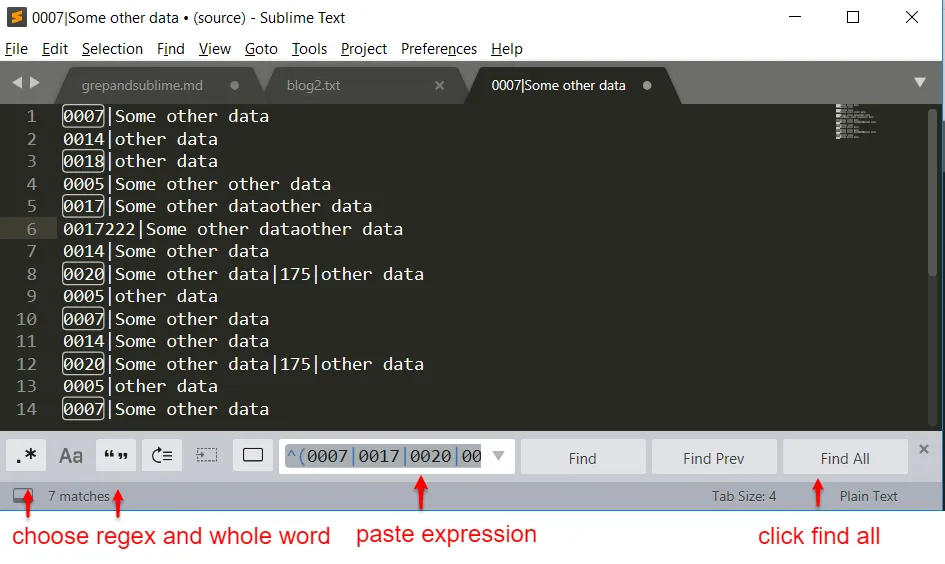
With these items selected I again used the multi-cursor features of sublime to select all of the lines I wanted and placed them in a new file.